
As a side-effect of the COVID-19 pandemic and social distancing, more people have turned to online platforms for social interactions.
Few memes actually become viral and it is unclear what characteristics lead a meme to have merit
With this, memes in the form of funny images, quotes, jokes, tweets and hashtags have become an even more important social phenomenon, catching the attention of sociologists and network scientists as well as data scientists like us.
Memes can express humor, thoughts, and draw attention to poignant cultural and political themes. Few memes actually become viral and it is unclear what characteristics lead a meme to have merit.
Many authors have explored the social network factors that lead a meme to go viral but bracketed the impact that meme content may have on popularity.
In contrast, our research performs a content-based analysis of what makes a meme successful using advanced machine learning techniques.
We scraped 129,326 unique image-with-text memes posted on Reddit during the beginning of the global coronavirus outbreak. The viral nature of image-with-text memes make this data well suited for a binary classification task.
Accordingly, we derived our target variable, which is dank (1) if a meme is in the top 5% of the number of upvotes divided by the number of subscribers to a subreddit, and non-dank (0) otherwise.
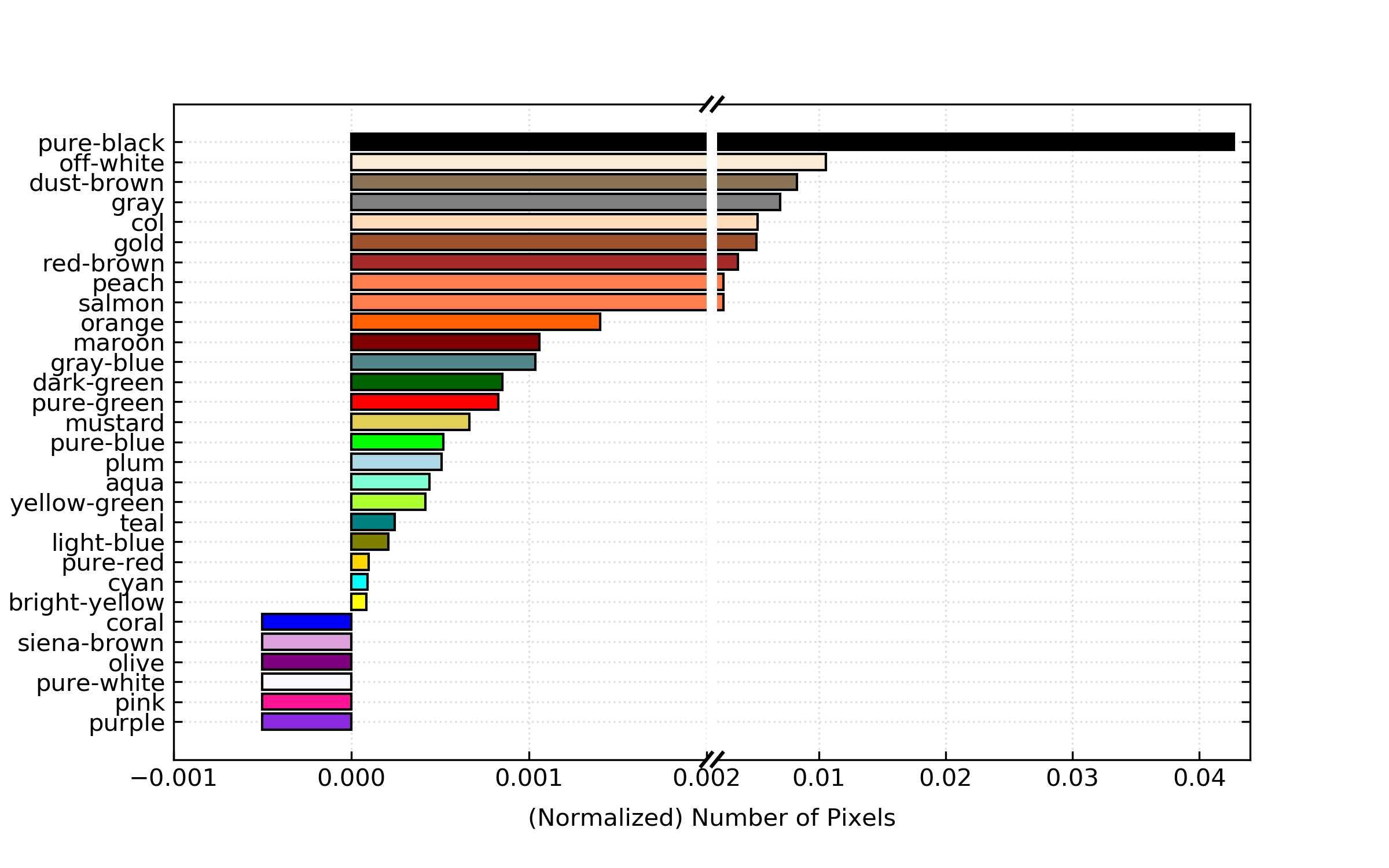
After data cleaning steps and explanatory analysis we used text analysis and optical character recognition to investigate the relationship between textual attributes and popularity.
The word cloud featured at the top of this post created from every word we gathered indicates certain topics are especially prevalent in the memes from late March 2020.
We found that in most cases, the most occurring words are just as prevalent in the top 5% viral memes as in the non-viral memes, except for the category COVID-19 synonyms which appeared more frequently in dank memes.
Surprisingly, it is not obvious whether image related or textual attributes have the stronger predictive power
We also analyzed low-level image attributes, such as color-content, hue, value, saturation, etc. and high-level image attributes that aim to describe the semantic meaning present in images.
We used three supervised learning models to predict whether memes fall into the dank or not dank categories: gradient boosting, random forest, and convolutional neural network.
The models were trained with image-only attributes, text-only attributes, both, and all attributes.
Not surprisingly, the model trained with all data outperformed the other models. This aligns with previous results in which text and network data held more predictive power for image popularity on Flickr.
Surprisingly, it is not obvious whether image-related or textual attributes have stronger predictive power since the Random forest model performed better with the image related attributes, while the Gradient Boosting model performed better with textual attributes.
We found that the success of a meme can be predicted based on its content alone moderately well; our best performing machine learning model predicts viral memes with an area under roc curve score of (AUC) 0.68.
We also found that both image-related and textual attributes have significant incremental predictive power over each other.
There are many great directions for future research relevant to this project such as analyzing memes inspired by COVID-19 alone or studying the temporal and dynamic aspects of meme success.

Comments