It’s hard to make predictions, especially about the Future.
Yogi Berra (via Titus Brown)
What will biology look like in the year 2039? In July I attended the Bioinformatics Open Source Conference (BOSC), a friendly community of open source advocates, where I heard bioinformatician Titus Brown deliver his thoughts on this in his talk, “A History of Bioinformatics (in the Year 2039)”.
Good for my jet lag and a great start to BOSC. Talks about the future often focus on data size. Titus pointed to one such talk by Mike Schatz of Cold Spring Harbor: “The next 10 years of quantitative biology”. (Also check out the latest big data Cold Spring Harbor meeting, whose abstract deadline is August 22nd.) Sequencing data is growing at the rate of 3x per year. Several people, including Titus and Mike, even point to automa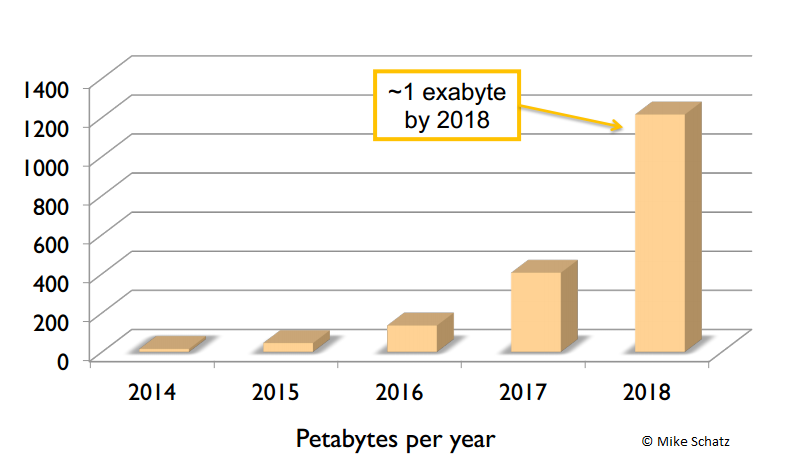 ted data collection—drones scanning the bottom of oceans and sequencing the air of all major cities.
ted data collection—drones scanning the bottom of oceans and sequencing the air of all major cities.
As neuroinformatics takes off with the Human Brain Project, which expects to generate yottobytes of data, and the increase of the use of big data imaging in areas like zoology, genomics will not be the only area of the biological sciences facing a ‘data tsunami’.
Titus, however, focused on a far less talked about aspect of this data tsunami: our inability to make anything of it. While our ability to gather data increases, our ability to use computational tools to draw conclusions from the data is sparse at best.
Although the easy-to-use computational tools might prove useful in the short term, they cannot substitute for true understanding. But perhaps it is this ‘black box’ problem—as it is exposed that such tools actually embody quite a few assumptions leading to errors—that will lead to the biggest revolution of biology.
In Titus’ history, it takes some time to register this as a problem. Funders are slow to recognise the importance of funding computational training. But they do. Slowly but surely, the term ‘bioinformatics’ disappears, to be replaced with ‘biologist’, as all biologists become computationally competent.
Training from such initiatives as @softwarecarpentry expand into @datacarpentry and @modelscarpentry. Before that happens, sweatshops of bioinformatics grad students processing the never-ending deluge of data flourish.
The biggest mistake proves to be withholding coffee. One step too far. As the sweatshops become unbearable, the great migration of the brightest of these data scientists to California begins. The Bay Area is transformed. Meanwhile, the peer review system becomes even more strained and those who are left revolt. The new rules to science are founded:
- All of the data and source code has to be provided for any computational part of a biology paper.
- Methods and full methods sections need to included in review.
- If an unpublished method was used in analysis of new data, a separate and thorough description and analysis must be made available at the time of peer review.
Open science becomes valued across the community in the midst of the mess that is left. Scientists begin to realise it is not the access to data that is the bottleneck, but the analysis of it. A new strategy of sandbagging competitors with data emerges. Titus points to quite a few possible developments, and I highly recommend watching the video of his talk which you can view below.
But here I want to turn to a more serious point I found particularly interesting. With the data deluge, one problem that surfaces is biology’s hypothesis-driven, rather than data exploration-driven, tradition. Indeed, this is how, from my perspective across the sciences, I see research changing most. As data becomes a resource existing in large explorable quantities from the start—ie, not after collection of specimens, analysis, etc—more and more scientists will turn to data exploration as a starting point. Questions rather than hypotheses will guide science.
This is in line with another point Titus makes: Prepare for poverty. “Winter is coming.” We need to maximise our resources. The obvious answer to that is to open up data for reuse, but in line with this research needs to become smarter. Doing more with less. Data exploration, to make the most of longer more expensive experiments and analyses, is part of that.
Comments