![]() The meta-genome is a 21st century concept, being first used in the year 2000 to describe a genetic library constructed from a mixture of soil micro–organisms. Further exploration of the genetic composition, function and expression of mixed microbial communities has accelerated at a dramatic pace, driven by the economy and ease with which next-generation sequence data-sets can be generated.
The meta-genome is a 21st century concept, being first used in the year 2000 to describe a genetic library constructed from a mixture of soil micro–organisms. Further exploration of the genetic composition, function and expression of mixed microbial communities has accelerated at a dramatic pace, driven by the economy and ease with which next-generation sequence data-sets can be generated.
In a timely overview of meta-genomics, Thomas et. al. provide an accessible primer for scientists who may be new to the research area, for example the ecologist, evolutionary biologist, microbiologist or clinician. The Review article, published in Microbial Informatics and Experimentation, introduces the typical steps in a meta-genomics research project, from DNA isolation and sequencing to data management and analysis.
Unique challenges to the sampling of meta-genomes are found in separating the fraction of genetic material of interest from the host (plant or animal) or other environmental DNA, as well as dealing with samples containing low quantities of DNA. The authors discuss the costs and error rates associated with widely used 454/Roche and Illumina/Solexa sequencing technologies and also look forward to the potential benefits of emerging methods.
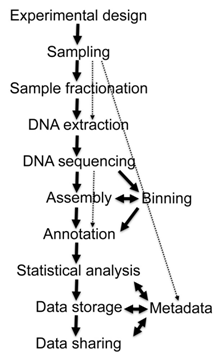 Pitfalls are described in using programs designed to assemble the genome of a single clonal organism for a mixture of many. Annotation of sequencing output from an entire community, rather than at a single genome level, also requires new tools. Custom platforms for meta-genomic data processing and sharing are brought to the fore, including MG-RAST, IMG/M, and CAMERA. The exchange and integration of meta-genomic data is led by the Genomic Standards Consortium (GSC) who aim to provide a standard data mark-up language and develop an ontology, within the OBO foundry, to promote data exchange with other research groups.
Pitfalls are described in using programs designed to assemble the genome of a single clonal organism for a mixture of many. Annotation of sequencing output from an entire community, rather than at a single genome level, also requires new tools. Custom platforms for meta-genomic data processing and sharing are brought to the fore, including MG-RAST, IMG/M, and CAMERA. The exchange and integration of meta-genomic data is led by the Genomic Standards Consortium (GSC) who aim to provide a standard data mark-up language and develop an ontology, within the OBO foundry, to promote data exchange with other research groups.
The review also draws useful analogies with statistical approaches used to compare genomes of higher organisms (already familiar to the evolutionary biologist or ecologist) as they can be applied to meta-genomic datasets. Whether a novice or not, this well-written “How-to” guide is free and essential reading for all meta-genome researchers.
Helen Whitaker
Latest posts by Helen Whitaker (see all)
- Biotechnology for a bio-based economy - 5th June 2019
- Sustainable energy at the American Chemical Society Spring meeting - 11th April 2018
- Biotechnology for Biofuels – Special Issue on Life Cycle Analysis - 17th May 2017
Comments