The Importance of Annotation: A Q&A with Hypothes.is Director of Biosciences, Maryann Martone
“To enable a conversation over the world’s knowledge” is the slogan for Hypothes.is, a open annotation layer that allows anyone to annotate anything. With an innovative open source tool, having the ability to annotate published work, be it data, methods or peer review comments, further enhances reproducible science and transparency – an ethos of GigaScience.
A New Coalition
Hypothes.is recently announced a coalition called “Annotating All Knowledge” with over 40 scholarly publishers, platforms and technology partners united with a shared goal of building a open conversation layer over all knowledge – also featured in Nature News. Having recently added Hypothes.is in our data repository,  GigaDB, GigaScience is pleased to be a partner journal in this coalition. As a partner, GigaScience and GigaDB understand that the open and interoperable layer will continue to evolve and align its capabilities with the motivations and interests of scholars and researchers guided by Hypothes.is’ 12 Principles. With the ability to annotate data in GigaDB, our repository will be contributing to the exploration required to understand how best to apply this interoperable layer over its content. Here, Maryann provides her personal insight into why annotation is so important and the mission of Hypothes.is. And some insight into why the Annotating All Knowledge coalition has started.
GigaDB, GigaScience is pleased to be a partner journal in this coalition. As a partner, GigaScience and GigaDB understand that the open and interoperable layer will continue to evolve and align its capabilities with the motivations and interests of scholars and researchers guided by Hypothes.is’ 12 Principles. With the ability to annotate data in GigaDB, our repository will be contributing to the exploration required to understand how best to apply this interoperable layer over its content. Here, Maryann provides her personal insight into why annotation is so important and the mission of Hypothes.is. And some insight into why the Annotating All Knowledge coalition has started.
The static scientific paper seems to have worked quite well for the last 300 years. Why is the ability to annotate so important?
Actually, annotation is an ancient and ubiquitous practice in scholarship. Some of our earliest manuscripts have scribbles in the margin. Annotated works are serious forms of scholarship, because they allow someone to provide additional insight into a work. The problem in the past was that annotations on top of physical works were destructive-how many times were we taught not to write in our textbooks when we were kids. With an electronic layer, we can peel the layer off or put it on as needed. I think it takes annotation into an entirely different realm.
What were your reasons for creating Hypothes.is? How does it differentiate itself from other plugins or sticky-note tools to markup and annotate web content?
The mission of Hypothes.is is “to enable a conversation over the world’s knowledge”. Early web pioneers had envisioned such a collaborative layer as part of the fabric of the web, but for various reasons, it was never done at scale. We have some bits and pieces in commenting systems, but these are patchwork and controlled by individual sites. Many are proprietary, so you can’t share annotated content across sites but only within specific contexts. And to achieve Hypothes.is’ mission, the annotations have to be shareable. But annotation, in my view, is very different than commenting, which tends to be presented as a scroll at the bottom of the page. It is anchored to very specific parts of documents as opposed to the entire document and is presented literally in the margins.
Our annotations are interactive to encourage conversations across time and space.
How does hypothes.is work for general users? Does a platform need to have hypothes.is enabled for users to annotate it, and users need to register and login to view or make annotations?
There are several different ways that individuals can use Hypothes.is. First, you can install the Chrome extension or one of our bookmarklets for other browsers so that you can activate Hypothes.is whenever you want. We’ve recently implemented a feature where the Chrome icon will display an annotation count if there are other annotations on a page. You need a free username and account for this, but the good news is that one account will annotate the web. You can share annotated documents with those who don’t have an account using our Via proxy service. Recipients can see annotations on these documents (provided they are not behind a paywall), although they will not be able to reply to them without an account. Finally, platforms can install Hyopthes.is so that it will be available to all users without having to install any extensions or plug ins. You will still need a Hypothes.is account-we’re working on linking to the host’s log in but it is not quite ready yet.
What sort of things should people annotate and what benefits does the ability to annotate present to the greater scientific community? Have you seen any killer examples highlighting the benefits of Hypothes.is yet?
I like to divide annotation into private and public activities. Hypothes.is is a great tool for taking notes on the web. I use it all the time in my research or just to make note of a mention of a book in an article or to highlight a quote. Because many annotations are searchable in my private stream, I can gather them up using appropriate tags. The uses really get interesting when the annotations are public. When you monitor the public annotation stream, you see different groups all around the world having scholarly conversations over works of fiction, news articles, research articles, books or even programming documentation. We are seeing great uptake in education, where teachers are incorporating collaborative annotation into the classroom. Jeremy Dean, the Director of Education at Hypothes.is, has done a great job in working with teachers and students. Hypothes.is is also being used by the AAAS in their Science in the Classroom project, where graduate students are annotating articles in Science to make them more accessible.
I joined Hypothes.is because I saw the potential in open annotation for addressing some of the current structural problems in biomedicine. We have so many articles scattered across so many journals and publishers. It’s very hard to provide enough information within the article to make the methods completely reproducible. With Hypothes.is, we can add a connecting knowledge layer on top of our current literature to add additional information or open up communication channels. So you could ask a researcher a very specific question about the methods, and the author could reply. Authors could update their own works – I have done this by annotating my own articles, providing additional information or backstories. In this way, we make them more accessible and turn them into living documents, even as the underlying text is enshrined for posterity. We are working with the Neuroscience Information Framework (NIF; Disclosure: I am one of the PI’s of NIF) to use Hypothes.is to pipe additional information about reagents and tools through the annotation layer. And, of course, annotation of the literature is a major activity in the biosciences with many databases and projects hiring curators to read the literature and extract structured information. We think Hypothes.is is an ideal tool for this.
Do you have any thoughts or plans on how the tool can be used to annotate data? As we’ve now implemented it for our GigaDB database have you seen any other examples of people using it to annotate this type of content yet?
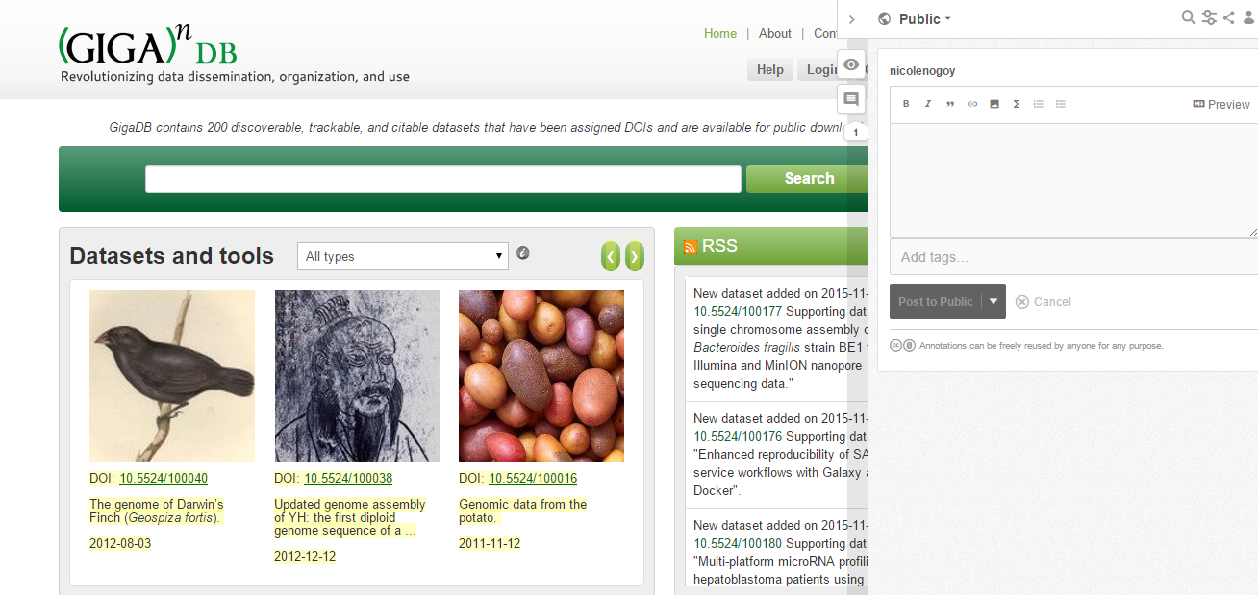
Annotating GigaDB with Hypothes.is
You are a pioneer, so I haven’t yet seen many examples of Hypothes.is for data beyond a few tests. Annotation is part of the entire scholarly workflow – we annotate our lab notes, our data files, our manuscripts, our papers. So I think the uses for data are similar to what we are seeing for text. I use Hypothes.is when I am exploring data sources, particularly across multiple databases, to keep track of items for later analysis. For static datasets, it works very well; we are still exploring requirements for more dynamic data. But it would be a great tool for data curation, where a curator can annotate the metadata and ask questions of the author. Anyone who might question a value or have additional things to link to a data item or set can do so via Hypothes.is.
For “hard core” data annotation, i.e., adding human knowledge to gene sequences, images, etc., I think that that Hypothes.is tools or open annotation would be of great benefit, as they would allow annotations to flow from one system to the next. Currently, Hypothes.is only works on text, but we are planning on incorporating annotation standards for images, videos and other data types.
What are the risks of spammers trying to hijack the Hypothes.is system? We for example have experimented with making editable supplemental tables using GitHub, so are there ways of balancing ease of use with spam prevention?
I’m afraid that I have to pass this one on to our technical team, but currently, they need to have a validated account and we have spam filters. But as always, with new technologies will come new ways to abuse them.
What upcoming plans and improvements do you have in mind for Hypothes.is?
Many! We just released our long-awaited Groups function so that people can annotate in private groups. In the immediate future, we will be integrating ORCID’s into annotations, both so that we can view profile information on annotators and so that annotators can get credit for annotated works. A very important feature for biomedical annotation is the ability to incorporate controlled vocabularies. That is also on the roadmap for the near future.